

توضیحات
آشنایی کامل با سیستم فایل توزیعشده هدوپ (Hadoop)
نام دوره : Data Engineering Master Course: Spark/Hadoop/Kafka/MongoDB
پیش نیاز:
- هیچگونه پیشنیازی وجود ندارد.
توضیحات
در این دوره، شما با سیستم فایل توزیعشده هدوپ (Hadoop Distributed File System – HDFS) و رایجترین دستورات مورد نیاز برای کار با این سیستم آشنا خواهید شد.
سپس به موضوع Sqoop Import پرداخته خواهد شد:
- چرخه عمر یک دستور Sqoop را درک خواهید کرد.
- با استفاده از دستور Sqoop Import، دادهها را از MySQL به HDFS منتقل خواهید کرد.
- با استفاده از دستور Sqoop Import، دادهها را از MySQL به Hive منتقل خواهید کرد.
- با فرمتهای مختلف فایل، فشردهسازیها، جداکنندههای فایل، شروط WHERE و کوئریها هنگام وارد کردن دادهها آشنا خواهید شد.
- مفهوم Split-by و Boundary Queries را درک خواهید کرد.
- از حالت Incremental برای انتقال دادههای جدید از MySQL به HDFS استفاده خواهید کرد.
Sqoop Export برای انتقال داده
شما در این بخش یاد خواهید گرفت:
- Sqoop Export چیست.
- با استفاده از Sqoop Export، دادهها را از HDFS به MySQL منتقل کنید.
- با استفاده از Sqoop Export، دادهها را از Hive به MySQL منتقل کنید.
Apache Flume
در این بخش، با Flume و نحوه استفاده از آن برای ورود داده آشنا میشوید:
- معماری Flume را درک کنید.
- با استفاده از Flume، دادههای توییتر را وارد کرده و در HDFS ذخیره کنید.
- با Flume دادههای بلادرنگ را از Netcat گرفته و در HDFS ذخیره کنید.
- دادهها را از Exec دریافت کرده و در کنسول نمایش دهید.
- با Interceptors در Flume آشنا شوید و مثالهایی از نحوه استفاده از آنها ببینید.
- از چندین عامل Flume برای ادغام دادهها استفاده کنید.
Apache Hive
در این بخش، شما با Hive برای مدیریت و تحلیل دادهها کار خواهید کرد:
- مقدمهای بر Hive.
- تفاوت بین جداول خارجی و مدیریتشده.
- کار با فایلهای مختلف مانند Parquet و Avro.
- فشردهسازی دادهها.
- استفاده از توابع متنی و تاریخ در Hive.
- پارتیشنبندی و تقسیم دادهها.
Apache Spark
Spark به عنوان یک ابزار کلیدی برای پردازش دادههای کلان در این بخش بررسی میشود:
- مقدمهای بر Spark و معماری کلاسترهای آن.
- درک مفاهیمی مانند RDD، DAG، مراحل و وظایف.
- آشنایی با اکشنها و ترنسفورمیشنها.
- کار با DataFrameها و استفاده از APIهای آنها.
- استفاده از Spark SQL برای کوئری دادهها.
- اجرای Spark در IntelliJ IDE و Amazon EMR.
- ادغام Spark با Cassandra.
Apache Kafka
Kafka برای مدیریت و پردازش پیامها در دادههای بلادرنگ:
- معماری Kafka، پارتیشنها و آفستها را درک کنید.
- با تولیدکنندگان (Producers) و مصرفکنندگان (Consumers) Kafka کار کنید.
- پیامهای Kafka را مدیریت کنید.
- از Kafka Connect برای ورود دادهها استفاده کنید.
MongoDB
این بخش شامل معرفی MongoDB و استفاده از آن در مدیریت دادهها میباشد:
- موارد استفاده MongoDB.
- عملیاتهای CRUD.
- کار با اپراتورها و آرایهها در MongoDB.
- ادغام MongoDB با Spark.
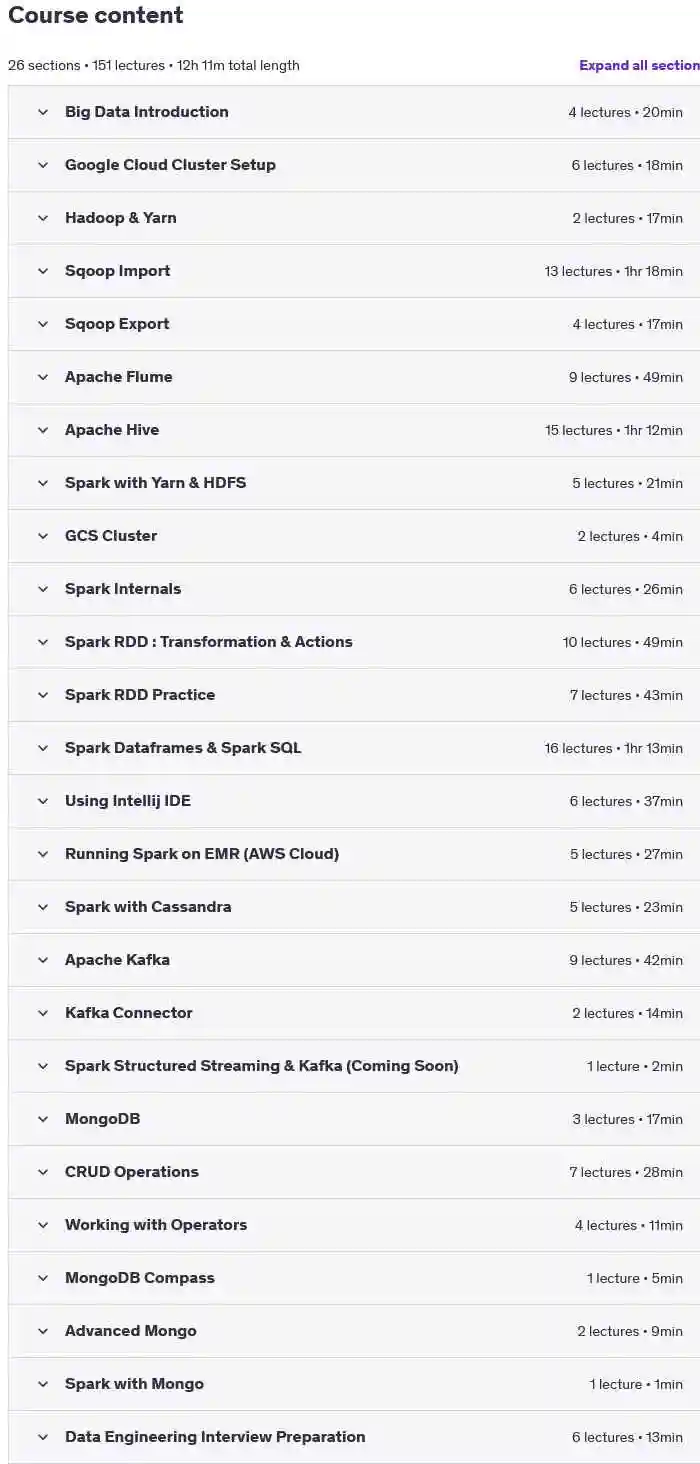
آمادگی برای مصاحبه مهندسی داده
در انتهای آشنایی کامل با سیستم فایل توزیعشده هدوپ (Hadoop)، شما برای مصاحبههای مهندسی داده آماده خواهید شد:
- سوالات مرتبط با Sqoop.
- سوالات مرتبط با Hive.
- سوالات مرتبط با Spark.
- سوالات عمومی مهندسی داده.
- سوالات مرتبط با پروژههای واقعی در مهندسی داده.
دوره آشنایی کامل با سیستم فایل توزیعشده هدوپ (Hadoop) برای چه کسانی است:
- افرادی که میخواهند فناوریهای دادههای کلان را یاد بگیرند.
- افرادی که به دنبال تبدیل شدن به مهندس داده هستند.




یودمی ایران –
دوره درخواستی خود را از راه های ارتباطی درخواست کنید