
")
توضیحات
آموزش کامل پیش نیاز های (Numpy) یادگیری ماشین
نام دوره : Deep Learning Prerequisites: The Numpy Stack in Python (V2+)
پیش نیاز:
- جبر خطی و توزیع گاوسی را درک کنید
- با کدنویسی در پایتون راحت باشید
- شما قبلاً باید بدانید که چرا چیزهایی مانند محصول نقطه ای، وارونگی ماتریس و توزیع های احتمال گاوسی مفید هستند و برای چه چیزی می توان از آنها استفاده کرد.
توضیحات:
این دوره برای پوشش پیش نیازهای یادگیری عمیق، یادگیری ماشین و علم داده است: پشته Numpy در پایتون.
یک سوال یا نگرانی که من زیاد متوجه شدم این است که مردم می خواهند یادگیری عمیق و علم داده را بیاموزند، بنابراین آنها این دوره ها را می گذرانند، اما از آنجا که به اندازه کافی در مورد پشته Numpy نمی دانند برای تبدیل آن مفاهیم به کد عقب می مانند. .
حتی اگر کد را به طور کامل بنویسم، اگر Numpy را نمی دانید، باز هم خواندن آن بسیار سخت است.
دوره آموزش کامل پیش نیاز های (Numpy) یادگیری ماشین برای حذف این مانع طراحی شده است – تا به شما نشان دهد چگونه کارهایی را در پشته Numpy انجام دهید که اغلب در یادگیری عمیق و علم داده مورد نیاز هستند.
پس آن چیزها چیست؟
شی مرکزی در Numpy آرایه Numpy است که می توانید عملیات مختلفی را روی آن انجام دهید.
نکته کلیدی این است که آرایه Numpy فقط یک آرایه معمولی نیست که در زبانی مانند جاوا یا C++ می بینید، بلکه در عوض مانند یک شی ریاضی مانند بردار یا ماتریس است.
این بدان معناست که می توانید عملیات بردار و ماتریس مانند جمع، تفریق و ضرب را انجام دهید.
مهمترین جنبه آرایه های Numpy این است که برای سرعت بهینه شده اند
. بنابراین ما قصد داریم یک نسخه آزمایشی انجام دهیم که در آن به شما ثابت میکنم که استفاده از یک عملیات بردار Numpy سریعتر از استفاده از لیست پایتون است.
سپس به چند عملیات ماتریس پیچیده تر مانند محصولات، معکوس ها، تعیین کننده ها و حل سیستم های خطی نگاه خواهیم کرد.
pandas عالی هستند زیرا کارهای زیادی را در زیر کاپوت انجام می دهند، که زندگی شما را آسان تر می کند زیرا دیگر نیازی به کدنویسی دستی آن چیزها ندارید.
اگر با R آشنایی دارید، Pandas کار با مجموعه داده ها را بسیار شبیه به R می کند.
شی مرکزی در R و Pandas DataFrame است.
ما بررسی خواهیم کرد که بارگذاری یک مجموعه داده با استفاده از Pandas در مقابل تلاش برای انجام دستی آن چقدر آسانتر است.
سپس به برخی از عملیات چارچوب داده مفید در یادگیری ماشین نگاه خواهیم کرد، مانند فیلتر کردن بر اساس ستون، فیلتر کردن بر اساس ردیف و تابع اعمال.
قالب های داده پاندا شما را به یاد جداول SQL می اندازد، بنابراین اگر پس زمینه SQL دارید و دوست دارید با جداول کار کنید، پانداها چیز بعدی عالی برای یادگیری خواهند بود.
از آنجایی که Pandas به ما می آموزند که چگونه داده ها را بارگذاری کنیم، گام بعدی بررسی داده ها خواهد بود. برای آن از Matplotlib استفاده خواهیم کرد.
در این بخش به بررسی برخی از نمودارهای رایج، یعنی نمودار خطی، نمودار پراکندگی و هیستوگرام خواهیم پرداخت.
همچنین نحوه نمایش تصاویر با استفاده از Matplotlib را بررسی خواهیم کرد.
در 99٪ مواقع، از نوعی از طرح های بالا استفاده می کنید.
Scipy.
من دوست دارم Scipy را به عنوان یک کتابخانه افزونه برای Numpy در نظر بگیرم.
در حالی که Numpy بلوکهای ساختمانی اساسی مانند بردارها، ماتریسها و عملیات روی آنها را ارائه میکند، Scipy از آن بلوکهای ساختمانی عمومی برای انجام کارهای خاص استفاده میکند.
به عنوان مثال، Scipy میتواند بسیاری از محاسبات آماری رایج، از جمله دریافت مقدار PDF، مقدار CDF، نمونهبرداری از یک توزیع و آزمایش آماری را انجام دهد.
دارای ابزارهای پردازش سیگنال است تا بتواند کارهایی مانند کانولوشن و تبدیل فوریه را انجام دهد.
دوره آموزش کامل پیش نیاز های (Numpy) یادگیری ماشین برای چه کسانی است:
دانشآموزان و متخصصان با تجربه کمی Numpy که قصد دارند بعداً یادگیری عمیق و یادگیری ماشینی را بیاموزند
دانشآموزان و متخصصانی که یادگیری ماشین و علم داده را امتحان کردهاند، اما در قرار دادن ایدهها در کد مشکل دارند
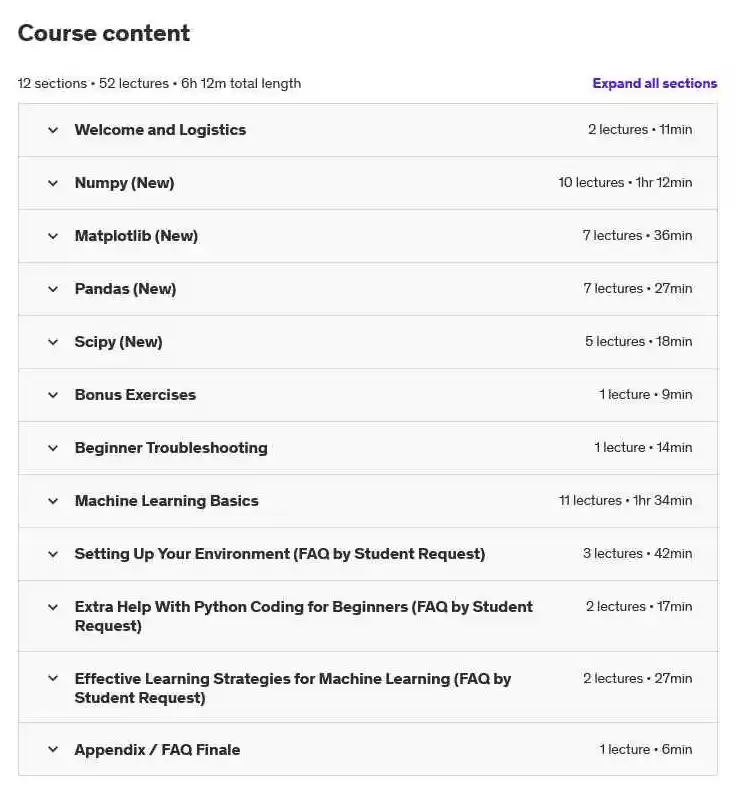
بخشی از دوره :



یودمی ایران –
دوره درخواستی خود را از راه های ارتباطی درخواست کنید